
About Me
Hello! I’m Manuel Alejandro Medina Cabrera, a dedicated Data Scientist and Software Engineer with a passion for turning data into actionable insights. With over five years of experience in the field, I have developed a unique blend of technical expertise and creative problem-solving skills that enable me to craft innovative solutions for complex data challenges.I hold a Bachelor's degree in Systems Engineering and a Master’s degree from Escola Politécnica da Universidade de São Paulo (USP), where I specialized in nonlinear mathematical models and data processing. My professional journey has taken me through roles at USP-LARC, Oliveira Trust DTVM SA and Mercado Livre Brasil, where I’ve led digital transformation initiatives, developed advanced machine learning models, and integrated AI-driven solutions into daily operations.
Skills

Hard Skills
Python, SQL (MySQL, PostgreSQL), NoSQL (MongoDB), SciKit-Learn, Pandas, PySpark, Data Lake, Data Warehouse, Matplotlib, Seaborn, Pattern recognition, NLP, Data mining, Tensorflow, PyTorch, Keras, Deep Learning, LLM, RAG, Big data, Big Query, Hadoop, Apache Spark, Data visualization, AWS Services, Airflow, Flask, Fast, Django, HTML, CSS, javascript, Git
Soft Skills
Experience with Business-to-Business (B2B) solutions.
Engage in brainstorming, team meetings and peer reviews
Creative and Critical thinking.
Open to learn and a strong commitment to safety, actively contributing to a safe working environment.
Experience executing projects, both working independently and as part of a cross-functional team.
Excellent written and verbal communication skills.
Featured Projects
Built Student Compass Platform
Founder & Lead Developer · 2026 – PresentDesigned and developed a full-stack career development platform using FastAPI and cloud infrastructure. Built a structured 7-step career journey system with scalable deployment, authentication, and analytics-ready architecture.


Developed a Q&A Chatbot:
Oliveira Trust Jan/2024 - may/2024Develop a Q&A chatbot for the company using embeddings of manuals, regulations, FAQs, and other necessary information to enhance the accuracy and relevance of responses through Retrieval-Augmented Generation (RAG).
Implemented a Legal Contract Information Extraction System:
Oliveira Trust jun/2023 - Dec/2023Designed and integrated a system to extract relevant information from legal contracts and link it with a notification system.


Automated Operations and Obligations Registration:
Oliveira Trust jun/2023 - Dec/2023Automatically registered operations and obligations post-contract review, reducing analysts' work time by 17%
Developed a Contract Analysis System:
Oliveira Trust Dec/2022 - May/2023Reduced analysts' work time by two-thirds through the creation of an efficient contract analysis system using LLM and NLP.


Built a Business Proposal Classification Model:
Oliveira Trust Oct/2022 - Dec/2022Assisted leadership in decision-making by developing a model to classify business proposals effectively.
Created an Anomaly Detection System for Investment Funds:
Oliveira Trust Jan/2022 - Apr/2022Enhanced security and compliance by implementing a system to detect unusual transactions in investment funds.


NBA (Next Best Action)
USP-LARC Jul 2020 - Jan 2022
Enhance data-driven decision-making, improve marketing efficiency, and boost customer engagement and satisfaction.
Education
Master en Data Analytics
University of Niagara Falls Canada (UNF)
Master of Data Analytics (MDA), September 2025- May 2027Relevant coursework:
Principles of Analytics; SQL Databases; Python for Data Analysis; Predictive Analytics; Data Warehousing & Visualization; Prescriptive Analytics; Advanced Data Visualization; Machine Learning; Capstone Project.
PhD in Systems Engineering
Escola Politênica da Universidade de São Paulo
August 2020 - October 2025Specialized in virus propagation in computer networks through nonlinear
mathematical models.Thesis: "Mathematical models of infection and propagation of viruses in computer networks"
Master's Degree in Systems Engineering
Escola Politênica da Universidade de São Paulo
August 2018 - October 2020Specialized in virus propagation in computer networks through nonlinear
mathematical models.Thesis: "Mathematical models of infection and propagation of viruses in computer networks"
Relevant coursework:
Applied Mathematics for Systems Engineering, Data Warehouse, Systems Identification
Bachelor's Degree in Automation Engineering
Universidad Tecnológica de La Habana 'Jose Antonio Echeverría' (UTH)
September 2012 - July 2017Focused on programming and optimization of product creation processes in technology companies.Final project: "Designed a native data acquisition board to obtain cardiac output and other hemodynamic parameters."Relevant coursework:
Control Systems, Microcontroller, Programming ,Industrial, Automation, Signal Processing, Electrical Circuits
Conclusion
Thank you for taking the time to explore my portfolio. With a robust background in Automation Engineering and Systems Engineering, coupled with extensive experience in data science and software development, I am passionate about leveraging technology to solve complex problems and drive innovation. My work is characterized by a commitment to excellence, a focus on impactful solutions, and a dedication to continuous learning and mentorship.I look forward to collaborating with like-minded professionals and organizations that share my vision for harnessing the power of data and technology to make a meaningful difference. If you have any questions or would like to discuss potential opportunities, please feel free to contact me.
© Untitled. All rights reserved.
Legal Contract Information Extraction System:
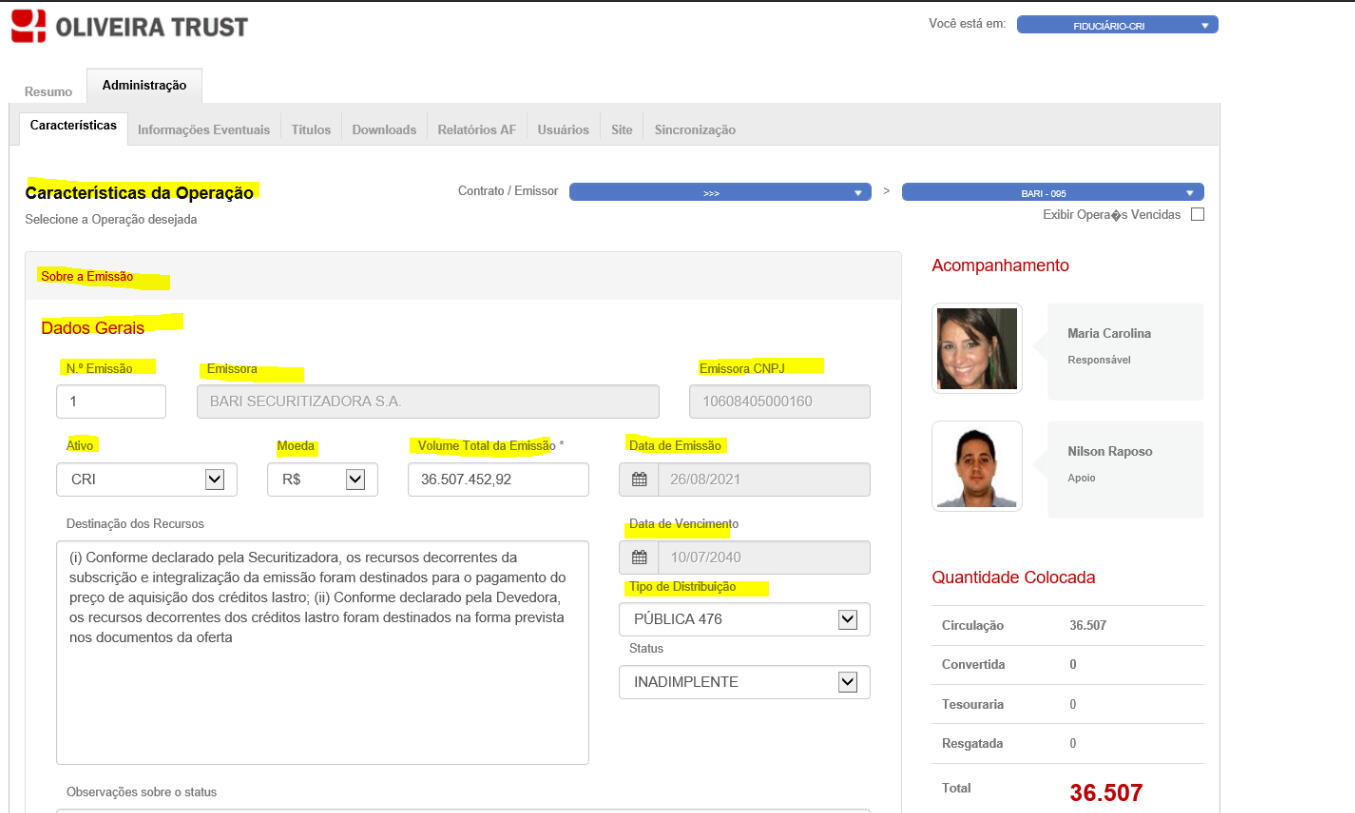
Project Goal:
Design and integrate a system to extract relevant information from legal contracts and link it with a notification system.
Key Steps to Create the Project
1- Requirement Analysis:
- Identify the types of legal contracts to be processed.
- Define the key information to be extracted (e.g., contract dates, parties involved, obligations, clauses).2- Data Collection and Preprocessing:
- Collect a diverse set of legal contracts for training and testing.
- Preprocess the contracts (cleaning, tokenization, normalization).3- Model Selection and Training:
- Choose suitable Natural Language Processing (NLP) models for entity recognition and information extraction (SpaCy).
- Train the models using labeled contract data to recognize and extract relevant information.4- System Design and Integration:
- Design the architecture of the extraction system, incorporating the trained models.
- Develop modules to process contracts, extract information, and store it in a structured format ( database MySQL).
Key Tools and Technologies
1- NLP Tools:
- SpaCy for entity recognition and information extraction.
- NLTK for additional text processing tasks.2- Data Storage:
SQL databases (MySQL) for storing extracted information.Development Frameworks:- Flask for building the web application.
- Vue.js 3 for frontend web page:
- Docker for containerizing the application.Version Control and Collaboration:
- Git for version control.
- Bitbucket for code collaboration and repository management.
Contract Analysis System: Project Overview
Project Goal:
Reduce analysts' work time through the creation of an efficient contract analysis system using Large Language Models (LLM) and Natural Language Processing (NLP).
Key Steps to Create the Project
1- Requirement Analysis:
- Identify the specific needs of analysts and the types of contracts to be analyzed.
- Define the key metrics for measuring efficiency improvement.2- Data Collection and Preprocessing:
- Collect a diverse set of contracts for training and testing.
- Preprocess the contracts (cleaning, tokenization, normalization).3- Model Selection and Training:
- Choose suitable LLMs (e.g., GPT-3, BERT) for understanding and analyzing contract content.
- Train models on labeled contract data to extract relevant clauses and information.
4- System Design and Integration:
- Design the architecture of the contract analysis system, incorporating the trained models.
- Develop modules to process contracts, extract information, and present it in an analyst-friendly format.
Key Tools and Technologies
1- LLM and NLP Tools:
- GPT-3 or BERT for language understanding and contract analysis.
- SpaCy or NLTK for additional text processing tasks.
2- Data Storage:
NoSQL databases (e.g., PostgreSQL, MongoDB) for storing extracted information and vector enbeddings.
2- Development Frameworks:
- Flask for building the web application.
Efficiency Tools:
- Airflow for workflow automation.
- Pandas and NumPy for data manipulation and analysis.
Chatbot Q&A Project for the Company

Project Goal:
Develop a Q&A chatbot for the company using embeddings of manuals, regulations, FAQs, and other necessary information to enhance the accuracy and relevance of responses through Retrieval-Augmented Generation (RAG).
Key Steps to Create the Project
1- Requirement Analysis:
- IIdentify the information needs of users.
- Define the types of documents and data to be integrated into the system (manuals, regulations, FAQs, etc.).2- Data Collection and Preprocessing:
- Collect a diverse set of contracts for training and testing.
- Preprocess the contracts (cleaning, tokenization, normalization).
- Preprocess the data, including cleaning, formatting, and structuring for embedding creation.3- Embedding Creation:
- Use NLP models (e.g., BERT, Sentence-BERT) to create embeddings for all documents.
- Store embeddings in a searchable database (MongoDB).4- Retrieval-Augmented Generation (RAG) Implementation:
- Integrate RAG architecture to enhance response generation.
- Configure the system to retrieve relevant document embeddings and generate accurate answers.Chatbot Development and Integration:
- Develop the chatbot interface using Flask.
- Integrate the RAG model to enable real-time Q&A capabilities.
Key Tools and Technologies
1- LLM and NLP Tools:
- BERT, Sentence-BERT, and OpenIA API for creating document embeddings.
- Hugging Face Transformers for integrating pre-trained models.
- LangChain Framework
2- Data Storage:
NoSQL databases (MongoDB) and FAISS for storing extracted information and vector enbeddings.
2- Development Frameworks:
- Flask for building the web application.
3- Efficiency Tools:
- Pandas and NumPy for data manipulation and analysis.4- RAG Implementation:
- PyTorch or TensorFlow for model training and inference.
- Hugging Face’s RAG implementation for integrating retrieval-augmented generation.
Automated Operations and Obligations Registration

Project Goal:
Automatically register operations and obligations post-contract review, reducing analysts' work time
Key Steps to Create the Project
1- Requirement Analysis:
- Understand the specific operations and obligations to be registered.
- Define the key metrics for measuring efficiency improvements.2- Data Collection and Preprocessing:
- Collect a diverse set of legal contracts for training and testing.
- Preprocess the contracts (cleaning, tokenization, normalization).3- Model Selection
- GPT-3 or BERT for language understanding and contract analysis.4- System Design and Integration:
- Design the architecture of the extraction system, incorporating the trained models.
- Develop modules to process contracts, extract information, and store it in a structured format ( database MySQL).
Key Tools and Technologies
1- NLP Tools:
- BERT, Sentence-BERT, and OpenIA API for creating document embeddings.
- Hugging Face Transformers for integrating pre-trained models.
- LangChain Framework2- Data Storage:
SQL databases (MySQL) for storing extracted information.Development Frameworks:
- Flask for building the web application.
- Vue.js 3 for frontend web page:
- Docker for containerizing the application.Version Control and Collaboration:
- Git for version control.
- Bitbucket for code collaboration and repository management.
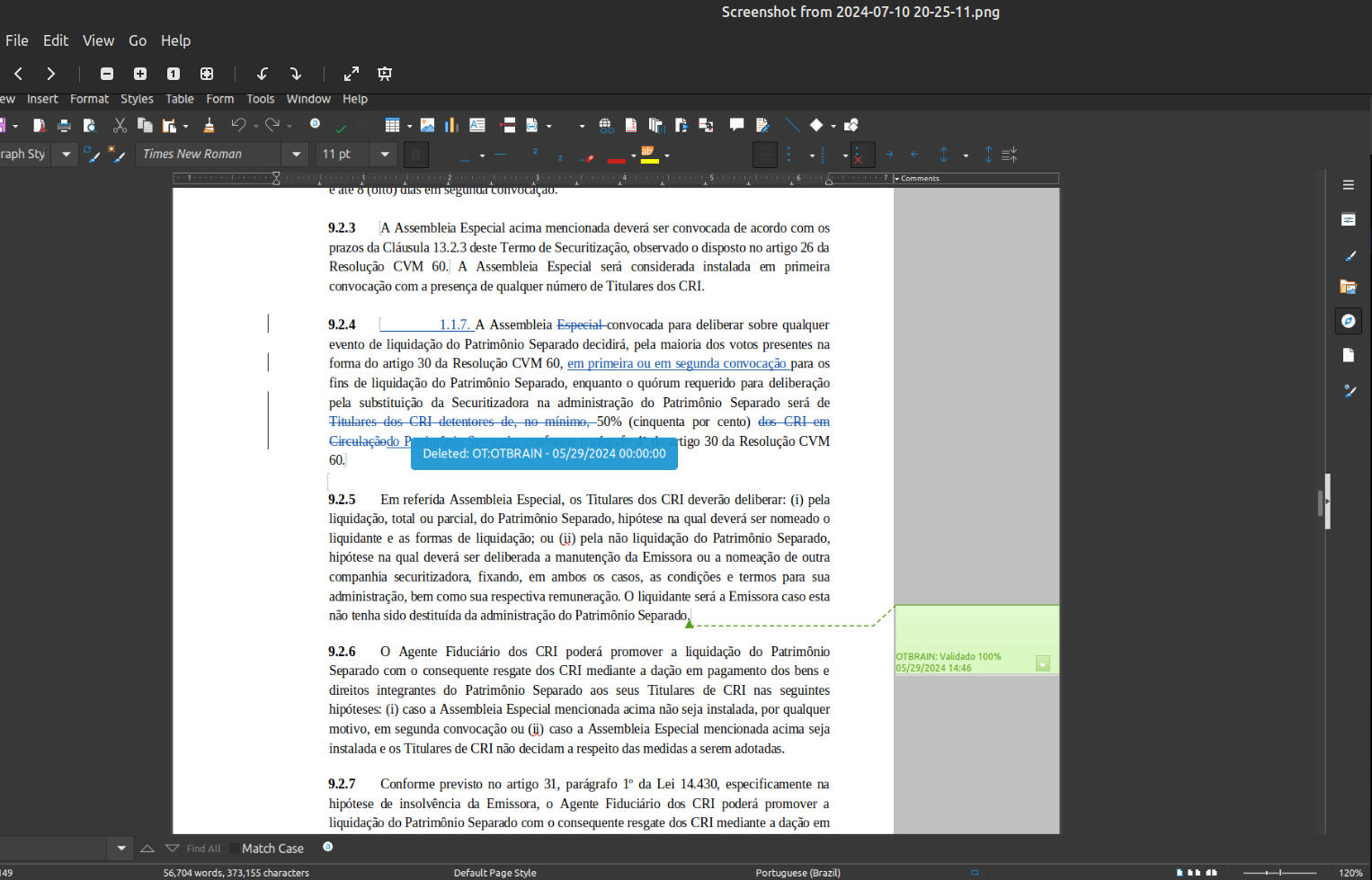
Business Proposal Classification Model
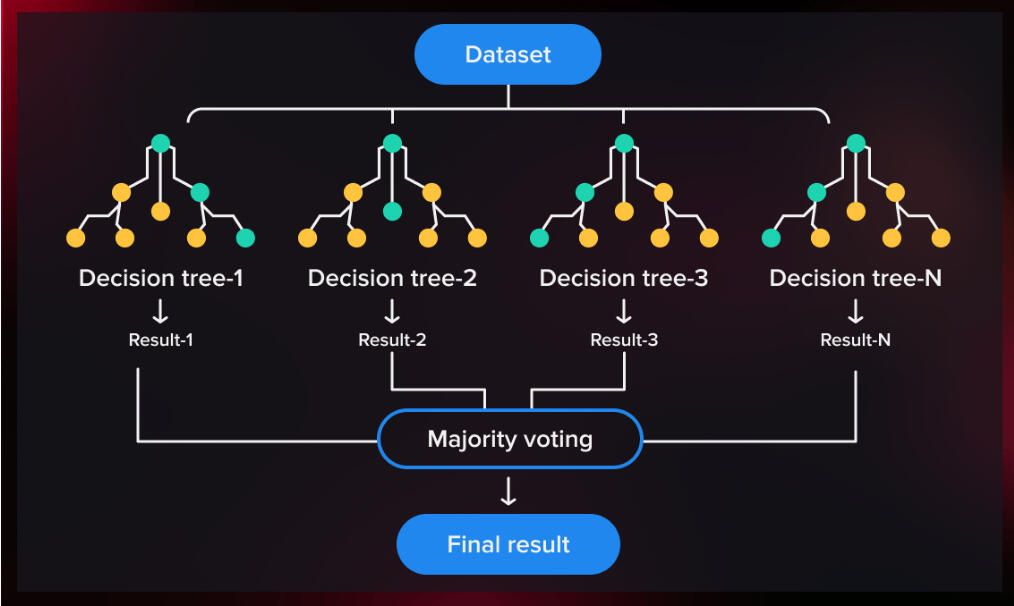
Project Goal:
Assist leadership in decision-making by developing an effective business proposal classification model.
Key Steps to Create the Project
1- Requirement Analysis:
- Understand the types of business proposals and classification criteria.
- Define key metrics for measuring the model’s performance.2- Data Collection and Preprocessing:
- Collect a diverse set of legal contracts for training and testing.
- Preprocess the data (cleaning, normalization, feature extraction).3- Model Selection
- Select relevant features for classification.
- Develop and train the Random Forest model using the preprocessed data.4- System Design and Integration:
- Design the architecture of the classification system, incorporating the trained model.
- Develop modules to input business proposals, classify them, and output results to leadership.Model Optimization:
- Tune hyperparameters and optimize the model for better accuracy and performance.
- Implement cross-validation to ensure the model’s robustness.
Key Tools and Technologies
1- Machine Learning Frameworks:
- Scikit-learn for developing and training the Random Forest model.
- Pandas and NumPy for data manipulation and preprocessing.2- Data Storage:
SQL databases (MySQL) for storing extracted information.3- Development Frameworks:
- Flask for building the web application.
- Docker for containerizing the application.4- Optimization and Validation Tools:
- GridSearchCV for hyperparameter tuning.
- K-fold Cross-Validation for model validation.5- Version Control and Collaboration:
- Git for version control.
- Bitbucket for code collaboration and repository management.
Anomaly Detection System for Investment Funds
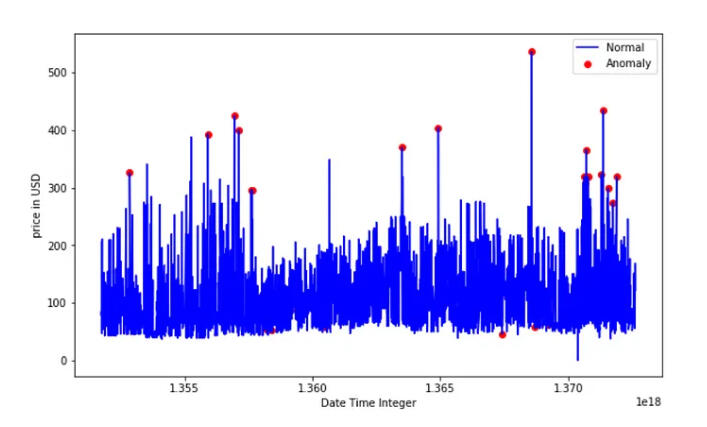
Project Goal:
Enhance security and compliance by implementing a system to detect unusual transactions in investment funds.
Key Steps to Create the Project
1- Requirement Analysis:
- Identify the specific types of anomalies and unusual transactions to be detected.
- Define the key metrics for measuring the system’s effectiveness2- Data Collection and Preprocessing:
- Gather historical transaction data from investment funds.
- Preprocess the data (cleaning, normalization, feature engineering).
- Perform exploratory data analysis (EDA) using statistical methods such as mean, median, standard deviation, and coefficient of variation (CV) to understand data distribution and identify potential outliers.3- Feature Engineering and Statistical Analysis:
- Generate new features that may help in identifying anomalies (e.g., transaction amount relative to the mean, rolling averages, z-scores).
- Apply statistical methods to analyze transaction patterns and detect early signs of unusual activity.4- Model Selection
- Select appropriate anomaly detection algorithms (Isolation Forest).
- Develop and train models using the preprocessed transaction data.
- Incorporate statistical methods such as moving averages and standard deviation thresholds for baseline anomaly detection.5- System Design and Integration:
- Design the architecture of the anomaly detection system, incorporating the trained models.
- Develop modules to process transactions, detect anomalies, and alert relevant stakeholders.6- Model Optimization:
- Tune hyperparameters and optimize the models for better accuracy and performance.
- Implement ensemble methods to improve detection rates.
- Use cross-validation techniques to ensure model robustness.
Key Tools and Technologies
1- Machine Learning Frameworks:
- Scikit-learn for developing and training the Random Forest model.
- Pandas and NumPy for data manipulation and preprocessing.2- Data Storage:
SQL databases (MySQL) for storing extracted information.3- Development Frameworks:
- Flask for building the web application.
- Docker for containerizing the application.4- Optimization and Validation Tools:
- GridSearchCV for hyperparameter tuning.
- K-fold Cross-Validation for model validation.5- Version Control and Collaboration:
- Git for version control.
- Bitbucket for code collaboration and repository management.
NBA (Next Best Action)
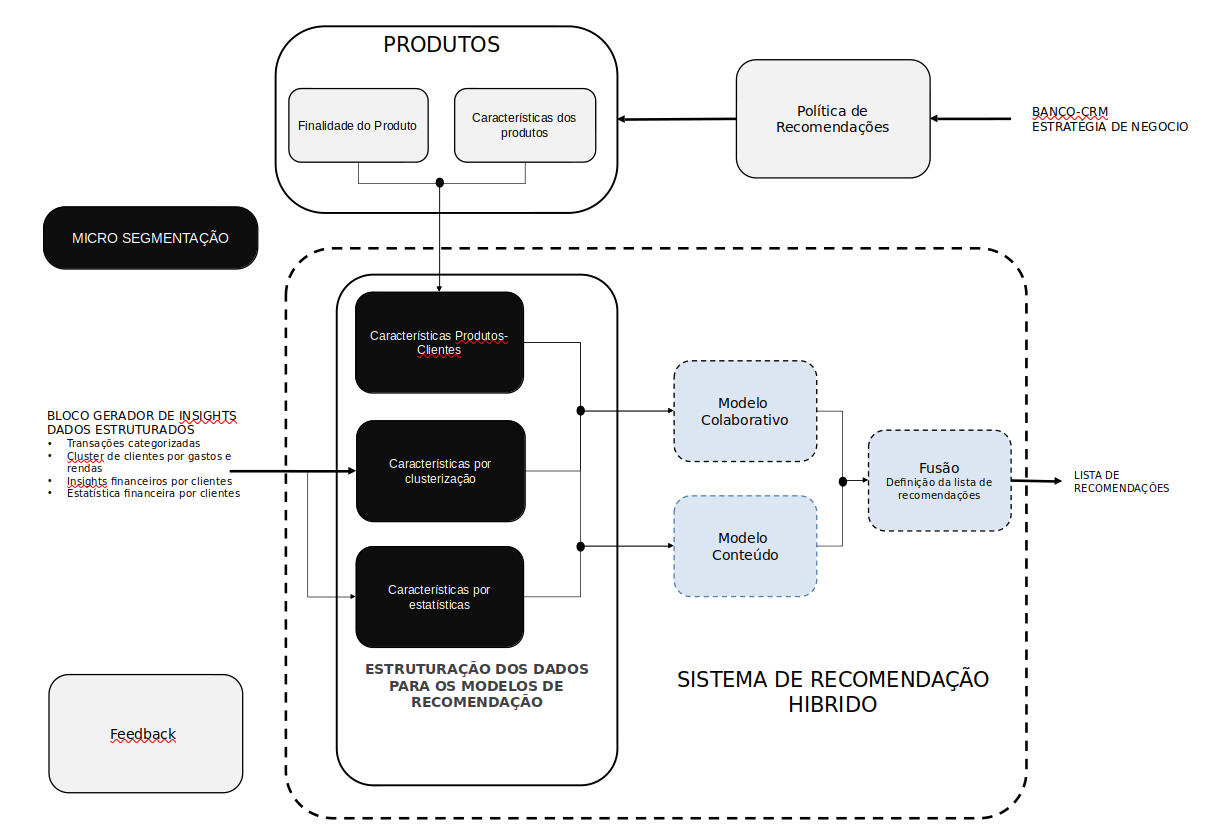
Project Goal:
Enhance data-driven decision-making, improve marketing efficiency, and boost customer engagement and satisfaction.
Key Steps to Create the Project
1- Requirement Analysis:
- Identify business objectives and key metrics for success.
- Define the scope of actions and decisions to be optimized by the NBA system.2- Data Collection and Preprocessing:
- Gather historical customer data, including interactions, transactions, and behaviors.
- Clean, normalize, and preprocess data to ensure consistency and quality.
- Perform exploratory data analysis (EDA) using statistical methods (e.g., mean, median, standard deviation) to understand data distribution and identify patterns.3- Feature Engineering and Statistical Analysis:
- Develop new features to capture important aspects of customer behavior and preferences.
- Apply statistical methods such as correlation analysis and regression to identify key drivers of customer actions.
- Use clustering techniques (e.g., K-Means, KNN, LSVC) to segment customers into distinct groups based on behavior and preferences.4- Model Development
- Develop clustering and regression models to understand and predict customer behavior.
- Experiment with different models such as Random Forest, Gradient Boosting, and Support Vector Machines to find the best fit for various tasks.
- Train recommendation models using algorithms such as collaborative filtering, content-based filtering, and hybrid approaches to suggest the next best actions for each customer segment.
- Integrate the models to create a comprehensive NBA system.5- Model Experimentation and Comparison:
- Implement and compare different clustering models (e.g., KNN, K-Means, LSVC) to find the most effective segmentation strategy.
- Test various regression and classification models to enhance prediction accuracy.
- Use performance metrics (e.g., accuracy, precision, recall, F1 score) to evaluate and select the best models.6- System Design and Integration:
- Design the architecture of the NBA system, incorporating all developed models.
- Develop modules to process customer data, generate recommendations, and deliver them through appropriate channels.7- Model Optimization:
- Tune hyperparameters and optimize the models for better accuracy and performance.
- Implement ensemble methods to improve detection rates.
- Use cross-validation techniques to ensure model robustness.
Key Tools and Technologies
1- Machine Learning Frameworks:
- Scikit-learn for developing and training the Random Forest model.
- Pandas and NumPy for data manipulation and preprocessing.
- SciPy for advanced statistical analysis.2- Data Storage:
SQL databases (MySQL) for storing extracted information.3- Development Frameworks:
- Flask for building the web application.
- Streamlit for creating interactive dashboards for marketing teams.
- Docker for containerizing the application.4- Optimization and Validation Tools:
- GridSearchCV for hyperparameter tuning.
- K-fold Cross-Validation for model validation.5- Version Control and Collaboration:
- Git for version control.
- Gitlab for code collaboration and repository management.
StudentCompass — Career Journey Platform (FastAPI)
Key Steps to Create the Project
OverviewStudentCompass is a web platform that guides students through a structured career-readiness journey (CV/LinkedIn optimization, resources, and progress tracking). It includes authentication, database-backed dashboards, file storage for user assets, and AI-powered features for matching and text understanding.Tech StackBackend: Python 3.13+ · FastAPI
ASGI Server: Uvicorn
Templates: Jinja2
Static Assets: Starlette StaticFiles
CORS: Starlette CORSMiddleware
Database & ORM: Async SQLAlchemy + Alembic migrations
Databases: PostgreSQL (asyncpg/psycopg) + SQLite (aiosqlite) for local/dev
Authentication: fastapi-users (JWT + cookies)
Configuration: python-dotenv
Storage & Media: AWS S3 (boto3) + ImageKit
AI / Embeddings: sentence-transformers · pgvector · google-genai
PDF / CV Processing: PyMuPDF
Scraping / Data Extraction: BeautifulSoup4 · Apify client
Testing: pytest · pytest-asyncio · httpx · pytest-cov
What I built (highlights)
Designed and implemented an async backend with FastAPI + SQLAlchemy async.
Built auth flows with JWT/cookies using fastapi-users.
Implemented database migrations and versioning with Alembic.
Integrated file/media storage using AWS S3 + ImageKit for delivery/optimization.
Added AI features using embeddings (sentence-transformers + pgvector) and LLM capabilities (google-genai).
Implemented PDF resume parsing using PyMuPDF.
Built scraping pipelines using BeautifulSoup and Apify for collecting structured data.
Added a test suite for async endpoints and coverage (pytest, httpx, pytest-cov).
KeywordsFastAPI, ASGI, Uvicorn, Jinja2, Starlette, Async SQLAlchemy, Alembic, PostgreSQL, SQLite, JWT, Cookies, AWS S3, ImageKit, Embeddings, pgvector, PyMuPDF, BeautifulSoup, Apify, pytest, async testing.